AI
Product
8 Min.
Generic AI vs. Specialized AI in MedTech: A Decision Framework

Immanuel Bader

Markus Müller

“Can’t we just use ChatGPT for this?”
It’s one of the questions we hear most often from regulatory and clinical teams evaluating AI tools. And honestly, it’s not a bad question.
Generic LLMs are fast, accessible, and often surprisingly useful. They help people think faster, draft faster, and get unstuck faster. Sometimes, that is exactly what a team needs.
But in MedTech, that question rarely stays simple for long.
Because in the end, the question is less about whether AI is useful and more about whether this particular kind of AI fits this particular kind of work.
Teams are often asking the wrong question
“Should we use AI?”
That conversation is already old news in most organizations. Many teams are already using AI in one form or another, whether they make a big announcement about it or not.
The better question is:
“What kind of AI is appropriate for this specific task?”
Because not every AI task in MedTech requires a specialized provider. But not every AI task is safely handled by a generic LLM either.
If the output is informal, low-risk, and disposable, generic AI may be perfectly fine. If the output becomes part of a documented workflow, a shared evidence base, or a regulatory process, the criteria change very quickly. At that point, “helpful” is no longer enough!
First things first: AI is not one thing
One of the most persistent mistakes in AI discussions is treating “AI” as if it were one single technology.
It isn’t.
Deep learning is not the same as machine learning, and machine learning is not the same as a large language model. Using those terms interchangeably is like calling every vehicle a car: fine in casual conversation, far too imprecise for sound decisions.
A few reminders make this clearer:
AI is not a truth engine.
It predicts plausible outputs based on patterns. That means it can sound polished, structured, and confident while still being wrong.Many teams already use AI without labeling it that way.
Translation tools, speech-to-text, transcription, and AI-assisted summarization are already part of everyday work in many organizations.There is no single universal AI validation checklist.
MedTech teams operate across overlapping expectations around software, quality, risk, validation, documentation, and increasingly AI-specific governance.
That’s why vague AI conversations go nowhere: If AI is not one thing, then AI tools should not be evaluated as if they were interchangeable.
Let’s be fair: generic LLMs are genuinely useful
This article is not anti-LLM – that would be lazy.
Generic LLMs can be very useful for low-risk, loosely structured tasks: brainstorming, rough drafting, rewriting, summarizing non-critical information, or simply helping one person move faster. If the goal is to sketch an outline, sharpen a paragraph, improve wording, or get quick orientation on a topic, a generic chat tool may be entirely sufficient.
And in those situations, dragging a specialized system into the picture can be unnecessary.
The point is not “generic bad, specialized good.” The point is fit for purpose.
What changes in MedTech workflows
This is where things start to shift.
In MedTech, outputs rarely stay casual for long: a quick summary can feed into a literature review, a drafted paragraph can end up in formal documentation, and even a seemingly minor conclusion may later need to be traced, explained, or defended.
That’s when the standard for judging AI changes.
Now the team has to think about reproducibility, source traceability, governance, persistence, consistency, validation, and audit readiness.
Once those questions show up, the evaluation can no longer stop at one simple standard: Was this answer useful in the moment?
It also raises a more subtle issue: how reliably outputs are grounded in actual source data, rather than just sounding plausible, since generic chat-based LLM usage is more prone to hallucinated outputs than structured systems that constrain and validate how results are generated.
Useful is easy, defensible is harder!
A practical decision framework for AI in MedTech
So how do you decide when generic AI tools are enough and when specialized AI makes more sense?
A simple framework starts with six questions.
1. What happens if the output is wrong?
This is usually the first and most revealing filter:
If the downside is minor, the output is just a rough draft, and the task is low-risk, a generic LLM may be completely fine. But if an error could affect evidence handling, compliance decisions, regulatory work, or quality-critical documentation, the tolerance changes very quickly.
The higher the consequence of error, the stronger the case for tighter control.
2. Does the output need to be traceable to source evidence?
Some tasks end with a useful answer.
Others require an answer that can be traced back to exact documents, exact passages, and exact evidence.
That’s a very different standard!
If no one needs source linkage, generic AI may be enough. If the output must be reviewable and defensible, traceability stops being a nice feature and becomes part of the job.
3. Is this an isolated task or part of a regulated workflow?
A one-off prompt is one thing. A recurring workflow is another beast entirely.
If the task sits inside literature screening, structured extraction, CER support, PMS-related work, or regulatory writing, then the workflow context matters just as much as the individual output.
Generic chat tools can help with steps. They are far less convincing when teams need support for the full process around those steps.
4. Does the work need to persist across time and across people?
A disposable chat session may work perfectly well for one person doing one quick task on a Tuesday afternoon. But that is rarely the full picture in MedTech, isn’t it?
Teams often need shared workspaces, searchable prior work, linked outputs, handovers across colleagues, and continuity across projects. Once work has to survive beyond one person and one session, the requirement shifts from a chat tool to a system.
5. Do you need validation support, release control, or documentation?
In regulated environments, many generic tools start to show their limits once validation, documented change behavior, release control, or supporting documentation are required.
That does’t make them useless, because it simply means they were not designed with this operating model in mind.
6. Are you solving a one-off productivity problem or building operational infrastructure?
This is the big one!
If the goal is ad hoc speed, generic AI may be exactly the right choice. If the goal is to build a repeatable, governed, team-wide workflow, then the conversation changes completely.
At that point, the team is no longer choosing a chatbot, but the infrastructure that will support regulated work. And infrastructure has to hold up under more pressure than a clever answer in a chat window.
What this looks like in practice
This gets much easier once the framework is applied to real tasks.
Generic AI may be sufficient for:
drafting rough internal notes
brainstorming arguments or structure
rewriting text for tone and clarity
summarizing a paper for first orientation
helping an individual move faster on a low-risk task
Specialized AI is usually the better fit for:
literature screening in a documented evidence workflow
structured evidence extraction for downstream regulatory use
generating text that needs exact citations and traceable linkage
recurring team workflows where outputs must remain searchable and reusable
work that may later need to be reviewed, validated, or defended
That’s the real dividing line: the more a task moves from temporary output to governed process, the less suitable a generic LLM usually becomes.
The deeper difference: productivity tool vs operational system
This is the distinction many teams feel long before they fully articulate it.
A specialized AI provider should support something much larger than individual, prompt-based tasks:
connected workflows
structured data continuity
source-linked outputs
controlled behavior
team-wide consistency
audit-ready processes
A useful shorthand is this:
Generic chat tools help with steps. Specialized AI helps operationalize workflows.
That difference matters because most MedTech teams are not struggling with one isolated step, but with fragmented workflows.
Search in one place. Read PDFs somewhere else. Track screening in Excel. Extract data manually. Write in Word. Share context over e-mail or chat. Then do the whole thing again next week.
The issue is often not intelligence, and it is not effort either!
The issue is that the workflow has been stitched together by hand across too many disconnected tools.
In that setting, a specialized AI system becomes something more substantial than a convenience layer: a system of record.
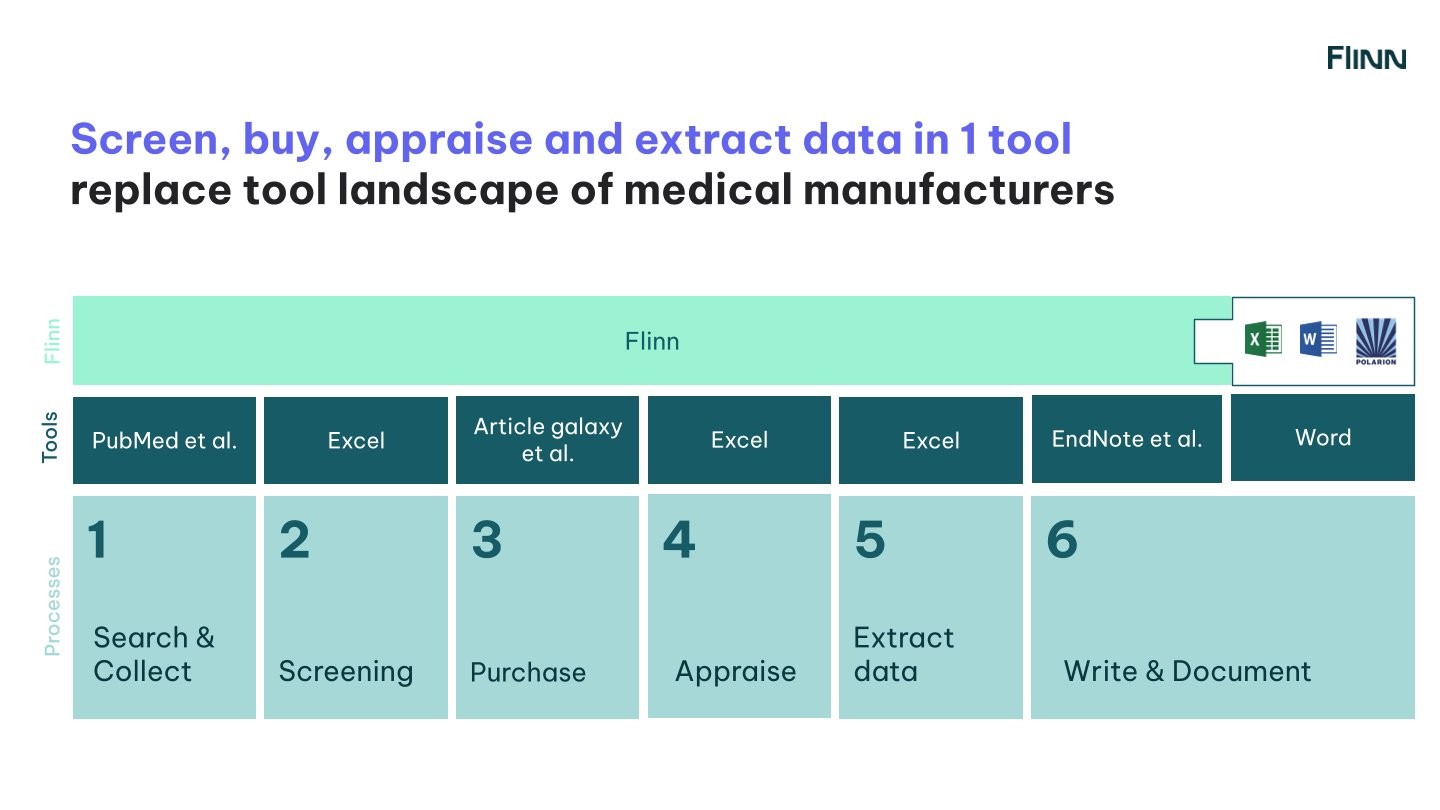
This is where the difference becomes visible: generic tools may help with individual tasks, but a specialized platform connects the workflow itself (from search and screening to extraction and writing) in one traceable system.
Disposable chat sessions vs a system of record
A chat session is useful because it feels immediate: you ask, it answers, and you move on.
But regulated work rarely ends there:
Teams need continuity. They need shared access. They need searchable history. They need linked outputs. They need a clear record of what was done, where it came from, and how it connects downstream.
Generic chat tools produce answers. Specialized MedTech systems should preserve context, structure, traceability, and continuity.
That is a much bigger promise, and in regulated workflows, it is often the more relevant one.
So when is ChatGPT enough in MedTech? Here’s the real answer
Short and sweet: Sometimes, absolutely!
If the task is informal, low-risk, and one-off, a generic LLM may be all you need. No need to overcomplicate it or drag a validated workflow platform into every tiny piece of thinking work.
But once the work needs to become repeatable, traceable, shareable, persistent, and defensible, the conversation shifts toward a much bigger decision: what kind of infrastructure should support regulated work.
So no, the real question is no longer:
“Should we use AI?”
That ship sailed a while ago. (By now, it is little more than a dot on the horizon.)
The better one is:
“What kind of AI is appropriate for this task, in this workflow, at this level of risk?”
If this is a decision your team is navigating right now, feel free to reach out anytime!
We would love to discuss this!













