AI
Produkt
9 Min.
Literaturrecherchen: Rationalisierung der Erkennung von Humanstudien

Shailza Jolly
29. März 2025
Johannes Leitner
29. März 2025

Die Herausforderung der Identifizierung von Humanstudien
Für Hersteller von Medizinprodukten ist die Einhaltung von Vorschriften nicht nur ein Kästchen, das man ankreuzen muss. Es ist eine ständige Herausforderung. Jedes Produkt, das auf den Markt kommt, muss wissenschaftlich untermauert werden, um seine Sicherheit und Wirksamkeit zu beweisen. Aber es ist leichter gesagt als getan, die richtigen Studien zu finden, nämlich solche, an denen Menschen beteiligt sind. Tausende von Zusammenfassungen zu lesen, um dann festzustellen, dass sich viele auf Tiere, Pflanzen oder In-vitro-Modelle konzentrieren, ist ein ineffizienter und zeitraubender Prozess. PubMed bietet zwar einen Filter für Humanstudien, ist aber mit einer Genauigkeit von nur 80 % bei weitem nicht perfekt. Das bedeutet, dass bedeutende Studien, die nicht am Menschen durchgeführt wurden, immer noch durchrutschen und ein manuelles Screening erforderlich ist, um relevante Forschung von irrelevanten Daten zu trennen.
Und genau hier kommen wir ins Spiel: Bei Flinn.ai haben wir einen automatischen Filter für das Screening von Abstracts entwickelt, der alle nicht-menschlichen Studien mit einer Genauigkeit von 99 % ausschließt. Durch die Nutzung der Leistungsfähigkeit von Large Language Models (LLMs) rationalisieren wir den Prozess der Literaturüberprüfung und ermöglichen es den Herstellern, sich auf die wirklich wichtigen Studien zu konzentrieren, Zeit zu sparen, den manuellen Arbeitsaufwand zu reduzieren und einen effizienteren regulatorischen Workflow zu gewährleisten.
In diesem Artikel befassen wir uns mit den Herausforderungen bei der Identifizierung von Humanstudien - eine Aufgabe, die auf den ersten Blick einfach erscheinen mag, sich aber sowohl für menschliche Experten als auch für KI-Modelle oft als überraschend komplex erweist. Wir untersuchen, warum diese Schwierigkeiten auftreten, wie unser Ansatz sie überwindet und welche greifbaren Vorteile er Medizinprodukteherstellern bietet, die ihren Literaturprüfungsprozess optimieren möchten. Sind Sie bereit?
Das Rauschen der Literaturrecherche durchdringen
Das Wichtigste zuerst: Wir verwenden den Titel und die Zusammenfassung einer wissenschaftlichen Veröffentlichung als Input und klassifizieren diese Inputs als Humanstudie und Nicht-Humanstudie. Hier ist ein Beispiel für einen Titel und eine Zusammenfassung einer Humanstudie:

Bei Flinn.ai haben wir einen Filter entwickelt, um diesen Prozess zu rationalisieren. Anstatt Zeit mit dem Screening irrelevanter Studien zu verschwenden, erkennt und entfernt unser System automatisch Studien, die nicht von Menschen stammen, und stellt sicher, dass nur relevante, von Menschen durchgeführte Forschung in Ihren Suchergebnissen erscheint. Mit dem Fokus auf 100 %ige Präzision minimiert unser System das Risiko falscher Ausschlüsse, sodass Sie sich darauf verlassen können, dass eine Studie, die herausgefiltert wird, wirklich nicht dazugehört.
Um ein Höchstmaß an Präzision zu gewährleisten, gehen wir an diese Herausforderung als ein Mehrklassen-Klassifizierungsproblem heran, das darauf abzielt, menschliche Studien von nicht-menschlichen Studien genau zu unterscheiden. Anstelle eines einfachen Ja-oder-Nein-Systems führen wir drei verschiedene Kategorien ein: ja, nein und unsicher. Dies ermöglicht eine höhere Genauigkeit in Fällen, in denen Mehrdeutigkeit auftritt. Wir definieren die einzelnen Klassen wie folgt:
Studie am Menschen
Ausdrückliche Erwähnung des Menschen (z. B. "Patienten", "Teilnehmer", "klinische Studie").
Menschen werden neben Tieren/Pflanzen/Mikroben erwähnt (z. B. "Menschen- und Mausmodelle").
Das Studiendesign impliziert die Beteiligung des Menschen (z. B. "randomisierte kontrollierte Studie", "In-vivo-Daten vom Menschen").
Nicht-menschliche Studie
Ausschließlich auf Tiere, Pflanzen, Mikroben, Insekten usw. bezogen (z. B. "in Mäusen", "Zellkulturen", "Drosophila").
Keine Erwähnung von Menschen oder vom Menschen stammenden Daten.
Unsicher
Zweideutige Formulierungen (z. B. "Probanden", "Proben" ohne Angabe von menschlich/nicht-menschlich).
Theoretische/mechanistische Studien (z. B. "molecular pathways", "in silico modeling") ohne klare Teilnehmer.
Die folgende Zusammenfassung dient als Beispiel für die Einstufung "Unsicher":

Methodik
Aufbau des Datensatzes: Ein tiefer Einblick
Unser Datensatz besteht aus 1.123 Paaren von wissenschaftlichen Titeln und Zusammenfassungen, die jeweils von Hand als Humanstudie beschriftet sind: Ja, Nein und Unsicher. Die Kategorie " Unsicher" war notwendig, um Fälle zu behandeln, in denen Abstracts vage Formulierungen verwenden oder sowohl menschliche als auch nicht-menschliche Elemente enthalten, was die Klassifizierung erschwert. In vielen Studien wird die Beteiligung des Menschen nicht eindeutig angegeben, was selbst für Experten Schwierigkeiten mit sich bringt.
Datenerhebung: Die Herausforderungen bestehender Datenbankfilter
Wir haben unseren Datensatz aus PubMed, einer der größten biomedizinischen Literaturdatenbanken, mit Hilfe von zwei booleschen Abfragen beschafft:
Eine Abfrage mit dem MeSH-Begriff "Animals" (Tiere) ergab nur 10 % der Tierstudien , was zeigt, dass bei einer ausschließlichen Verwendung von MeSH-Begriffen viele nicht-humane Studien unentdeckt bleiben würden.
Eine zweite Abfrage unter Verwendung von "Animals" AND NOT "Humans" ergab 80 % der Tierstudien - ein Hinweis darauf, dass die Standardkategorisierung von PubMed immer noch erhebliche Überschneidungen zulässt.
Die wichtigsten Erkenntnisse aus der Datenerhebung
Die MeSH-Begriffe von PubMed allein sind nicht geeignet, um nicht-humane Studien herauszufiltern - ihre Anwendung würde zu viele relevante humane Studien ausschließen.
Die Suchergebnisse unserer Nutzer unterscheiden sich von unseren - wir haben absichtlich einen experimentellen Datensatz erstellt, der Studien über Insekten, Pflanzen und Viren enthält. Unsere Nutzer verwenden restriktivere Suchanfragen.
Die Genauigkeit unseres KI-Modells ist eine untere Grenze - da unser Datensatz viele schwierige Randfälle enthält, erwarten wir, dass das Modell bei realen MedTech-Suchen noch besser abschneidet.
Datenaufteilung: Training, Validierung und Test
Um sicherzustellen, dass unser KI-Modell zuverlässige und unverfälschte Ergebnisse liefert, haben wir den Datensatz in drei Teilmengen aufgeteilt:
Trainingsdaten - Werden zum Trainieren des maschinellen Lernmodells verwendet und liefern ein grundlegendes Verständnis der Studienklassifizierung.
Validierungsdaten - Werden zur Feinabstimmung und Optimierung des Modells verwendet, um sicherzustellen, dass es über den Trainingssatz hinaus verallgemeinert und eine Überanpassung vermieden wird.
Testdaten - Ein völlig ungesehener Datensatz, der für die abschließende Bewertung verwendet wird, um sicherzustellen, dass das Modell bei neuen Veröffentlichungen genau funktioniert.
Die folgende Tabelle zeigt die Verteilung der Klassen für die Zug-, Validierungs- und Testdaten. In den Testdaten ist die Anzahl der nicht-humanen Studien (Spalte "Nein") die bei weitem größte Klasse.

Modellierung: Training der Software zur Klassifizierung von menschlichen und nicht-menschlichen Studien
Schritt 1: Nutzung von großen Sprachmodellen (LLMs)
In einem ersten Schritt haben wir mit mehreren Large Language Models (LLMs) experimentiert, sowohl mit Open-Source- als auch mit proprietären Modellen:
Zero-Shot Prompting - Das Modell macht Vorhersagen ohne vorherige Beispiele und verlässt sich dabei ausschließlich auf sein vorher trainiertes Wissen.
Few-shot prompting - Eine kleine Anzahl von beschrifteten Beispielen wird bereitgestellt, um das Verständnis des Modells zu unterstützen.
Dynamisches Multi-Shot Prompting - Das Modell passt seinen Ansatz anhand mehrerer Beispiele an und verfeinert seinen Klassifizierungsprozess in Echtzeit.
Durch Prompting können wir die KI anleiten, ohne ihre internen Parameter zu verändern, und so die Flexibilität bei unterschiedlichen Datensätzen gewährleisten. Durch die sorgfältige Ausarbeitung von Anweisungen und die Bereitstellung von Beispielen aus realen Studien konnten wir dem Modell helfen, Schlüsselindikatoren für die menschliche Beteiligung an wissenschaftlichen Studien zu erkennen.
Schritt 2: Feinabstimmung für Präzision
Als Nächstes haben wir mehrere Open-Source- und proprietäre LLMs anhand unserer Trainings- und Validierungsdaten feinabgestimmt. Anders als beim Prompting werden bei der Feinabstimmung die internen Gewichte des Modells angepasst, sodass es direkt aus unserem Datensatz lernen kann.
Schritt 3: Interpretation von AI-Entscheidungen
Während der Experimente erstellen wir zusammen mit dem Klassifizierungsergebnis auch die Begründung für die Klassifizierung durch das LLM. Dieser Ansatz ermöglicht es uns, obwohl wir keine Domänenexperten sind, zu beurteilen, ob der Rückgang der Genauigkeit auf das LLM oder auf eine falsche Grundwahrheit zurückzuführen ist. Das Modell mit der höchsten Genauigkeit bei den Test-/Validierungsdaten war eine feinabgestimmte Version eines vortrainierten Modells - es ist auch das Modell, das derzeit in Flinn.ai verwendet wird. Im nächsten Abschnitt sehen wir uns die Leistungsergebnisse genauer an.
Ergebnisse: Messung der AI-Leistung beim Literaturscreening
Bewertung der Modellleistung
Wie stellen wir sicher, dass unser KI-Modell zuverlässig zwischen menschlichen und nicht-menschlichen Studien unterscheidet? Indem wir die Leistung des Modells systematisch anhand von Schlüsselkennzahlen bewerten:
Genauigkeit - Wie oft stimmen die Vorhersagen des Modells mit der tatsächlichen Klassifizierung überein.
Präzision - Der Prozentsatz der als nicht menschlich eingestuften Studien, die korrekt identifiziert wurden.
Recall - Die Fähigkeit des Modells, alle relevanten nicht-humanen Studien zu finden.
Eine unserer obersten Prioritäten ist es, sicherzustellen, dass keine relevanten Humanstudien fälschlicherweise herausgefiltert werden. Deshalb wird zusätzlich zu den drei Metriken auch für die nicht-menschlichen Studien die Präzisions-Nicht-Mensch-Studie berechnet.
Den Faktor "Unsicherheit" ansprechen
Große Sprachmodelle (LLMs) neigen dazu, das unsichere Label seltener zuzuweisen. Um dies zu berücksichtigen, haben wir eine zusätzliche Metrik eingeführt:
Filtered-Precision-Non-Human-Study (Precision-no-F) - Diese Metrik entfernt unsichere Fälle und berechnet die Präzision nur auf der Grundlage eindeutiger menschlicher und nicht-menschlicher Klassifizierungen.

Ergebnisse in der realen Welt
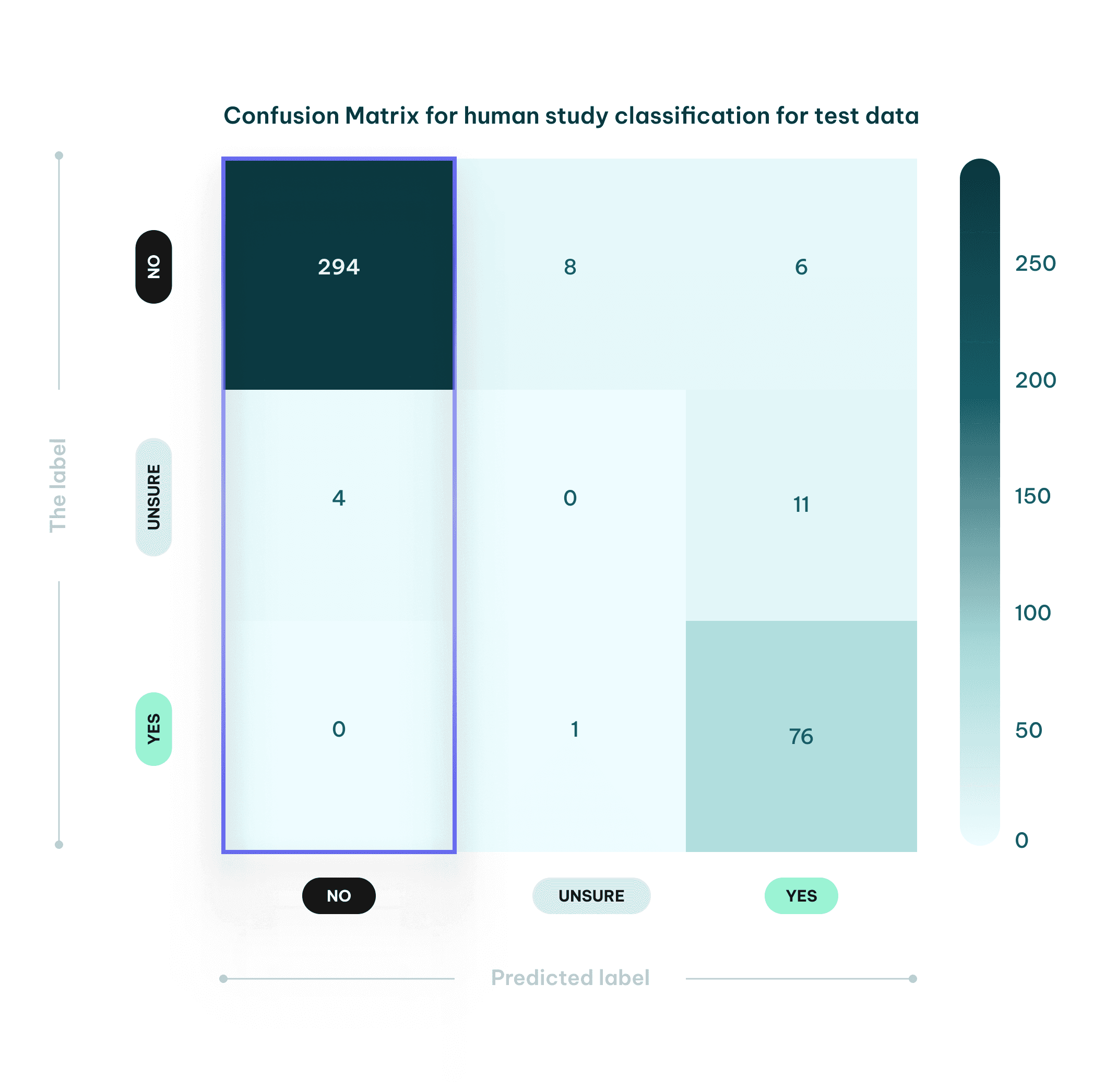
Wie in der nachstehenden Konfusionsmatrix dargestellt, stufte unser KI-Modell 298 Studien als nicht-menschlich ein: 294 Einstufungen waren korrekt, 4 Fälle wurden als "Unsicher" markiert - diese Zusammenfassungen waren zu mehrdeutig und erforderten eine Volltextanalyse für eine korrekte Klassifizierung. Diese unsicheren Fälle werden nicht herausgefiltert und dem Benutzer zur Bewertung überlassen.
Herausforderungen beim AI-gestützten Literaturscreening
Selbst die fortschrittlichsten Modelle stoßen auf Hürden, wenn es darum geht, zwischen menschlichen und nicht-menschlichen Studien zu unterscheiden. Zwei große Herausforderungen stechen hervor:
Zweideutige und unklare Zusammenfassungen
Wissenschaftliche Zusammenfassungen sind nicht immer klar formuliert. Viele Studien verwenden eine vage Terminologie oder geben nicht ausdrücklich an, ob menschliche Probanden beteiligt waren. Dies führt zu Grenzfällen, in denen selbst menschliche Prüfer bei der Einstufung unterschiedlicher Meinung sind.
Um dieses Problem zu lösen, haben wir einen zusätzlichen Fachmann hinzugezogen, der die falsch eingestuften Fälle überprüft.
Interessanterweise schloss sich der Experte häufig der KI-Klassifizierung an und nicht den ursprünglichen menschlichen Anmerkungen.
Dies deutet darauf hin, dass die den wissenschaftlichen Zusammenfassungen innewohnende Subjektivität bei der Klassifizierung eine wichtige Rolle spielt.
Einschränkungen des Datensatzes: Die PubMed-Lücke
Unser Modell wurde zunächst mit Daten aus PubMed trainiert, wobei boolesche Abfragen verwendet wurden, um nicht-menschliche Studien zu erfassen. Dieser Ansatz führte jedoch zu einer entscheidenden Diskrepanz:
Der Datensatz enthielt Studien über Pflanzen, Viren und Insekten, die für MedTech-Hersteller kaum relevant sind.
Diese ungewöhnlichen Fälle erschwerten die Klassifizierung, da viele Abstracts nicht in die Standardkategorien passten, die beim Screening von Literatur in der Praxis vorkommen. Wir gehen davon aus, dass unser Modell bei Kundendaten besser abschneidet, wo solche Randfälle wahrscheinlich seltener vorkommen.
Flinn.ai: Wo wir stehen
Bei diesem Modell war unser Ziel die Erkennung von Humanstudien für das Abstract-Screening - und durch den Einsatz von Large Language Models (LLMs) konnten wir den manuellen Arbeitsaufwand erheblich reduzieren, die Präzision erhöhen und den Abstract-Screening-Prozess rationalisieren.
Bis zu 30 % schnelleres Screening von Abstracts - Unser Ansatz ermöglicht es den Nutzern, nicht-menschliche Studien effizient herauszufiltern und so wertvolle Zeit und Mühe zu sparen.
99 % Genauigkeit - In PubMed-Datensätzen hat unser Modell eine nahezu perfekte Genauigkeit bei der Erkennung von nicht-humanen Studien gezeigt.
Verbesserte Compliance und Effizienz - Die Automatisierung des Literaturscreenings reduziert menschliche Fehler und stellt sicher, dass kritische menschliche Studien nicht übersehen werden.
... und was kommt als Nächstes?
Gut, dass Sie fragen! Unsere nächsten Schritte umfassen:
Ausweitung auf die Volltextanalyse - Die Einbeziehung von frei zugänglichen Veröffentlichungen ermöglicht eine höhere Präzision, da vollständige Studiendetails und nicht nur Zusammenfassungen berücksichtigt werden.
Verfeinerung der KI mit realen MedTech-Daten - Das Training auf branchenspezifischen Datensätzen wird die Relevanz und Genauigkeit weiter verbessern.
Verbesserung der Benutzerfreundlichkeit und Anpassung - Optimierung der KI-Funktionen zur besseren Anpassung an unterschiedliche Benutzerbedürfnisse und gesetzliche Anforderungen.
Angesichts der zunehmenden behördlichen Anforderungen war der Bedarf an einer schnellen und präzisen Literaturrecherche noch nie so groß wie heute. Sind Sie bereit, Ihren Prozess der Literaturrecherche zu rationalisieren? Lassen Sie uns reden!













